 HiepPham's Blog
HiepPham's Blog

Before going through this blog, I would like to inform that this blog is reposted from a technical blog that I have read. Please enjoy the content and this blog is not commercial.
How Karpenter Works
Karpenter is a fairly new autoscaler, , claimed as “Just In Time Nodes” for Any Kubernetes Cluster.
Currently Karpenter just support AWS and Azure. You need to write your own piece to support other cloud provider.
Karpenter works by evaluating pending pods, batch them and evaluating the total required resources, and then talking to EC2 fleet directly. Behind the scenes, it chooses 60 of the most efficient Instance Size, and then try to provision them based on their availability.
Karpenter has also the ability to “deschedule” pods, move them to other nodes if they deemed that the current setup is inefficient. This process is called consolidation. Consolidation can happen in two scenarios:
- If workload(s) inside a node may be moved to another node without spawning a new one
- If workload(s) inside a node may be moved to a newly spawned node that is smaller than the current Node.
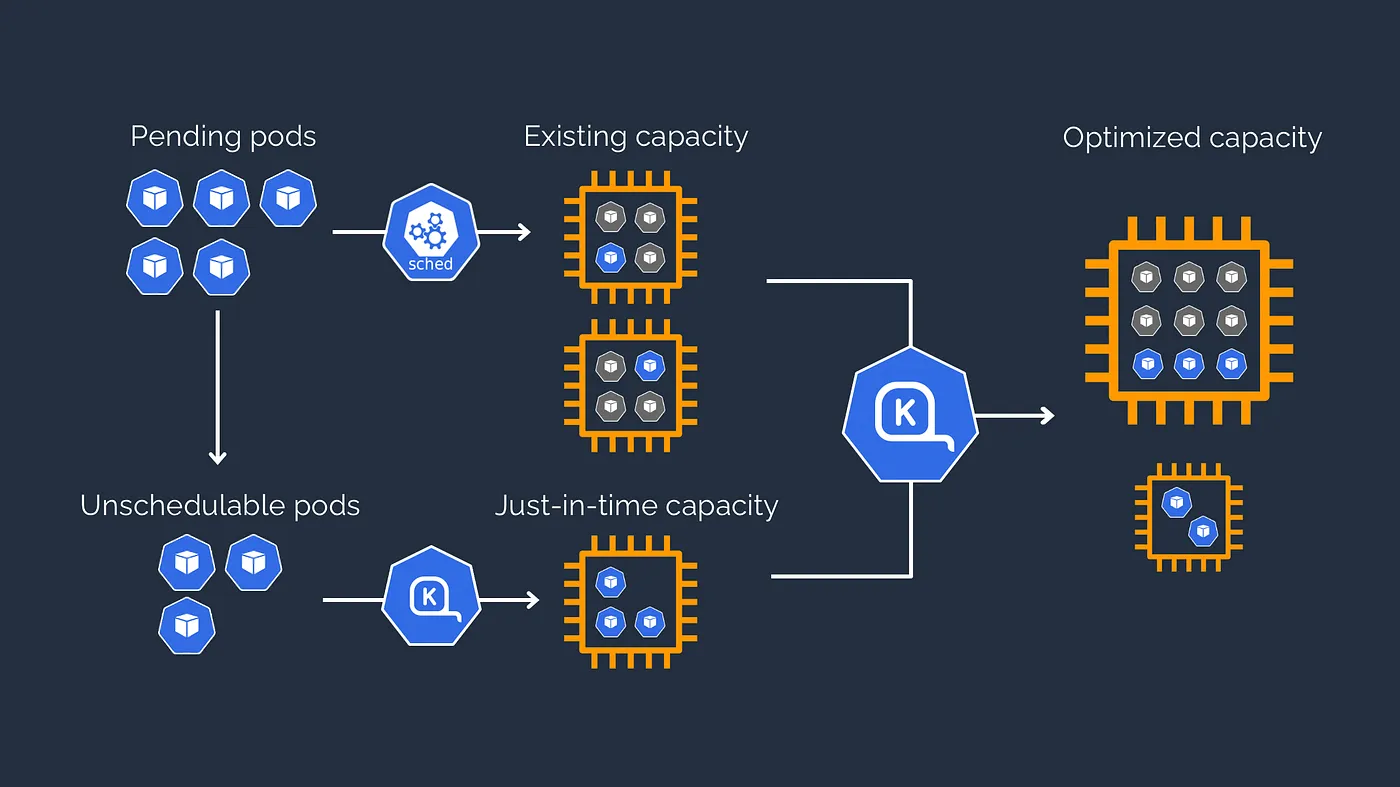
Karpenter vs Cluster Autoscaler
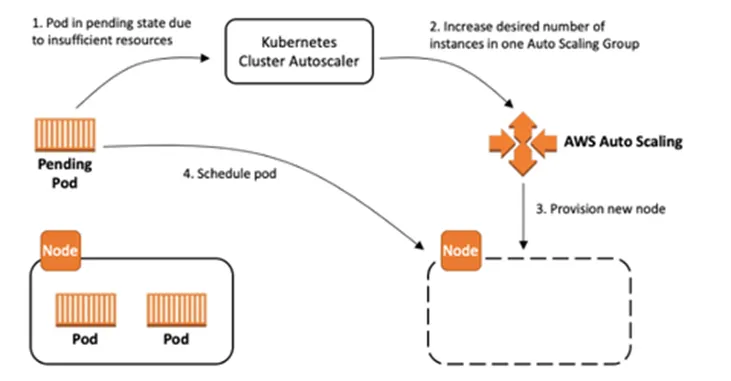
Here is a diagram on How Cluster Autoscaler works:
The main difference that I felt during my time using karpenter are:
Karpenter are able to directly to talk to EC2 Fleet API. This means that it has a lot more flexibility, compared to Cluster Autoscaler that relies on Autoscaling Group as a template for the provisioned instances, means the limitation that is on Autoscaling Group will be a limitation on Cluster Autoscaler as well. While talking directly to EC2 API doesn’t have significant performance difference, the ability to dynamically choose instance based on the needs of the cluster is a huge plus in the operational expenses. There are no need to play the guessing game on what instance to use on a cluster. We can simply say, we want to use C,M,R instance, and only T instances that have more than 16Gi Memories.
Karpenter is a tool that is well equipped to efficiently scale in and out, with full functions to be able to handle interruption events and deschedule pods properly. In the contrary, Cluster Autoscaler is a tool that designed solely for increasing and decreasing the nodes. It doesn’t thinker around the kubernetes part too much. For example, if we are only using Cluster Autoscaler, descheduling are not handled properly here, leaving nodes like a swiss-cheese. We need another tool for that, like Descheduler . Or another tool that may be handy for Cluster Autoscaler is AWS Node Termination Handler , to handle when there are termination events in the AWS side.
In my experiences, Karpenter performs faster than Cluster Autoscaler. Karpenter needs only 40 seconds counted from the Pods are unable to be scheduled inside the cluster, until a new node is ready to serve. Cluster Autoscaler waits until the whole cycle of evaluation to provision/deprovision node. In my observation, this took around 2–3 minutes until the node is fully ready or the node is gone after it is not needed. Note that this may be implementation issue, therefore take it with a grain of salt.
Learning Situation
Workloads failing because Lack of Resources
At the first iteration when we are trying to implement things on the development environment, suddenly we are hit with a ton of mentions, complaining about the environment are unstable, intermittently got 5xx errors.
Upon checking, turns out PostgreSQL, the database that is depended by a lot of service, is constantly being evicted by Kubernetes. Turns out all of database in development environment doesn’t have resource request set. This will make that karpenter thinks that it requested 0 resources, and will provision the smallest node possible, and when the workloads run, their usage exceeded the amount that the node can handle, therefore being evicted by Kubernetes, and this goes on and on.
The solution is pretty simple, configure the resource request properly. A little side note that Karpenter only accumulates resource request as a parameter, it doesn’t account the resource limit when provisioning the instances.
Overheads are Expensive
The idea when running a Karpenter-enabled cluster is that we will reserve as high as possible resources, decreasing the number of excess resources provisioned in a cluster. The way we implemented is by using a lot of smaller nodes, contrary to previously we use less-amount bigger nodes. After implementing this, we realize that overheads are expensive. System Overheads includes system workloads (kubelet etc), and DaemonSets. While system workloads are not really manageable, We can decide how much DaemonSet we want to run.
DaemonSet means that for every node that runs in a cluster, there will be a pod running there, hence with a lot of smaller nodes, the number of uses resource to run DaemonSet will increase as well.
The solution of this is to just re-think, do we need DaemonSet to run things? Some workloads may serve the purpose as well by running it on a Deployment. If needed, then go ahead, but if not, try to think other solution.
Services died because of Karpenter Activity
As explained earlier, Karpenter has a feature called consolidation. Consolidation essentially terminates pods and move them around to bin pack the environment better. Also there are also activity regarding spot instance reclaim, in the case where the environment has implemented spot instances. This sometimes lead to 5xx.
At a thought process level, What i learn here is that we need to understand that Disruption must be embraced when dealing with Kubernetes. Therefore, we must configured the service properly to be able to handle the disruption. What we implemented here to embrace the disruption is:
- Configure the PDB minAvailable, to ensure that there will always be a pod running. The number of minAvailable of PDB should be at minimal one less than the Minimal Replicas of the HPA, to ensure that there are rooms for disruption so Karpenter can evict the pod.
- Configure the PreStop Hook, to be able to handle SIGTERM better. One interesting info that we found when experimenting this is when a Pod receives a SIGTERM, the sidecar proxy died first before the service container, therefore any attempts by the service to finish ongoing process are failed since all outgoing request will fail.
References
- https://medium.com/@farissatyaw/karpenter-what-is-it-and-here-is-the-gotchas-cfcfd3df7cf3 (Original Post)
- https://karpenter.sh/
- https://home.robusta.dev/blog/stop-using-cpu-limits
- https://kubernetes.io/docs/concepts/scheduling-eviction/api-eviction/